What skills to teach researchers?
The idea:
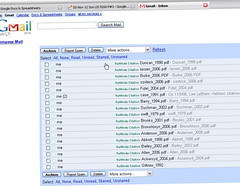
Use RefWorks to manage citations & gmail as web database to collect research documents (articles, images, scanned pages from books, etc...).
The system can do this because we separate the documents from their descriptive identifiers:
--gmail to contain pdfs, and
--Refworks to hold citations.
Goals:
-- augment, unify, improvise new elements,
-- and adapt the best ideas in each design,
-- share, share, share: the golden days of the lone researcher are done -if they ever truly existed.
The major problem with current systems:
-- the continuing explosion of research, worldwide,
-- inconsistency in design and execution,
-- the different "export" formats for data with no standardized xml-like structure, (even if they say they do, it's rare to not have to clean up your data),
-- and lack of centralized storage mediums for collected documents in any format,
-- very few user advocates.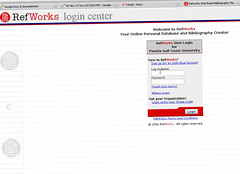
A Proposal for a Distributed Citation Management Information System: CMIS:
That's just some fancy name/acronym that uses web resources to make aggregated citations & digitized documents available anywhere & shareable. Here we look at the information system in terms of its usage, intended audience and features. The information system described below capitalizes on currently existing designs and technologies in information systems. I've not come up with anything new here: just re-mixed some ideas already out there. I know some systems offer this service, kinda.
Specific Process:
1.1 Our intrepid researcher conducts a search in a full-text-database or on the internet.
1.2 As the researcher finds citations & collects the full-text documents, those items could be stored remotely.
1.1a. The researcher could upload this file into a web-based storage medium. This web-based storage medium could serve triple duty
-- as a repository for the files,
-- as a means to back up files as we all face the potential of local, catastrophic data loss,
-- as a means to keep accessible/feed the collected citations and documents -think rss.
1.3 The researcher chooses RefWorks to manage the citations as it’s web-based & allows for semi-clean exporting.
1.3a. The researcher opens a gmail account with the name: Smith.documents@gmail.com
1.4 Next, the researcher renames the full-text pdf with this specific naming convention:
--"Last Name of Author Year.pdf" and uploads to gmail
1.4a. A researcher collecting thousands of articles, naming files arbitrarily or using the article title or using keywords and having to remember what they signify fails at a large a scale of documents.
1.4b. Adhering to a strict format encourages a consistent file naming structure and the use of a search engine to find the articles in a time of need. Browsing through nested folders on a personal computer could be likened to “filunacy” not to mention abysmally time wasting. Having to remember why you titled a file "Information Management" when it is about Florida Citrus in the 1930's may not make sense. Yet, if you use an information strategy combined with a search document repository where you properly cited and included metadata you might find that in an article from the 1903’s on citrus a quote that caught your attention and succinctly expressed how all the world is information -even in the eyes of a citrus farmer. 
These two elements combined create a (web-based) citation manager and (web-based) document repository. Removing the need for storage on a personal computer
-- frees one to gain access to research anywhere in world,
-- allows anyone to share their research by encouraging soft collaboration.
Soft collaboration could mean an RSS feed to stream new research back into the library's OPAC or databases. This means a researcher could choose to be shown research other collected citation "containers" from fellow researchers via a feedback into a database.
The containers may have research citations of interest to anyone collecting similar research. Potentially another researcher could have already spent hours collecting documents on say, "Design of Information Systems." Seeing those citation containers collected along with a scholar's ongoing search will address the questions Tague-Suttcliffe and Saracevic put forth about interactivity retrieval and the need to not ignore this integration into search.
What this allows is a highly scalable design of simplicity, usability and the most important "small, low rules for learnability." Students will learn:
-- research is cumulative,
-- can be re-cycled, and
-- planning out research saves time at the end.

As OPACS and other online search systems become "smart" to
--allow users to contribute,
--make data portable across systems,
--and expose empty, disjointed spaces rather than disallow actions
the integration with much larger information systems (think web of interconnected citations) presently in existence or to be created in the future will increase collaboration. While the parts are not highly integrated into one web-based platform, we do have portability and opt-out abilities in some systems. A universal citation format for all disciplines/ document types wouldn't hurt either.
Design and usage:
Several citation collection systems exist. Most of the current systems have one component of what is addressed below. As an example, current citation management systems will keep citations organized but not the documents they describe. This is not to mention another issue where the researcher gets little help in the pragmatics:
--naming files,
--creating folders
--or instruction the best way to organize the collected documents.
If these current systems capitalized on the research of information organization perhaps the realization of aiding the researcher or defaulting to a "safe mode" would be transparent. Actual, practical aid to researchers on these matters is slim.
Current systems:
-- are either web accessible from any computer
-- or only accessible from a single desktop computer, and are
-- rarely both.
This is of no aid to researchers who wish to share their knowledge. The personal citation systems typically link to the articles stored locally on a personal computer and do not have a universal, off-site repository for the documents they describe. Buckland describes a document as something that will constantly evolve AND of which new forms may be introduced AND most importantly can serve as a sign to relate meaning. Usually though we find a document having a dual nature depending on its context (Buckland, 1997). The Shibboleth project & a central repository for uploading documents would go very, very far in aiding research. The OCLC is working on something like this for ILL.
This dude Saracevic's idea of context and the need for information scientists to get on the same page if not within the same document space rings true: gonnnnnnnnnnnnnnng. Saracevic asks, "How successful was and is information retrieval in resolving the problem of information explosion in the area applied (Saracevic, 1995)?” The research documents I'm choosing to discuss here are pdfs file formats. The collection system proposed can hold any media, in any form, for collection, storage, and retrieval. Currently, the only limit may be the size of the file. Some materials may need to be converted to a suitable electronic format for storage and delivery.
Since all the pieces already exist what the researcher is looking at is a method of organization, representation, retrieval and relevance that is highly achievable. Being part of larger organization systems much of the information infrastructure lies in place. To further extend this idea the current export links in any type of database could be massaged to externally or internally launch a container to capture the scholar's research importing or interfacing with either desktop software or web-based accounts. At first the researcher has to learn to use the different elements.
Future iterations of this information design will see the integration of these steps into the search process. Another point is that once learned these elements free a researcher to devise their own citation system or use existing systems. Making searching, collecting, and organizing operate like a well-greased wheel will only create an easier research process for all types and levels of scholarship.
Intended audience:
Our intended audience for this scheme of information organization and representation are first year college students just entering the world of research. The idea is to break research into two steps: search and collection management. The initial step is for our first year college students to search for sources of information. Then those students are to manage the collected sources of research to make it immediately valuable by organizing the information and making it accessible. Doing so helps develop core research skills needed for in depth research projects such as the ability to manage large pieces of information over an extended period of time.
Primarily, this information organization and system can be used for any age college student within their first year of college. The immediate focus is freshman, first year, or first time in college students. Our intended age range could be the typical eighteen year old traditional freshman or fifty year old non-traditional student. The best results and sustained use will come from marketing towards and for first year students as they are unlikely to have any information management skills. Centering on this strategy encourages and allows student to learn proper sequence for research and teaches students to break research into steps. In time, research on the CMIS would show it fosters a larger, or systems-orientated view of information management.
Although this discussion was tapered to blending with existing information systems, information professionals could use closed, pay-for-access services, free software, open source software, web-based software and or a combination these methods in designing an information system and teaching researchers to manage information. Actions like these create knowledge of the larger world of scholarship, steps that go into research, and helps create fluency across mediums rather literacy with one medium or type of tool -think here of a for-purchase piece of software such as Endnote. These techniques can be formalized into a software system and becomes another tool student’s use regularly; students grow their research sources and begin to understand the need to manage their information life as they go through college and into their professional career. Integrating current information systems this way or creating an information system that helps complete research steps put the research process as part of writing process as part of information management. This strategy starts students early with information management and places the library, the internet, software other university systems, or an information commons as tools students use to conduct research.
Intended features:
This CMIS information system is designed to integrate with a library web site, a university web site and an email web site. The features include benefits such as portability of various pieces of information. Citation containers can appear along side other research results. Clickability is maximized as researchers’ doubts are minimized. Those doubts can be framed as "Others conducting searches on your keywords collected these citations" links.
Citations, papers, and other research sources can be shared through this method as it encourages dynamic use of research. Students can more easily access and share with their research with fellow students at the same time seeing what others search for. In using the existing OPAC, databases and it is necessary only to add a third component: information management of research sources. Those components which we discussed consist of an email account that serves as a document repository, a citation manager software piece and the learnable strategy to use these components to mange citation and documentation. Each piece could be embedded as links within the databases.
Clicking on a link could serve to launch an external connection to the established web-based accounts via a proxy server. Seamlessly transitioning the data would be the goal but in cases where this could not be achieved it would desirable to have the data exportable in a standard plain text format, xml format, bibtex format, tab delimited format, or ris format. Having this variety would ensure compatibility across several information systems, allow for retrieval, and sharply increase the chance that, in the present or future sense, the citation and documentation will only gain relevance.
Design and usage are intermixed and linked. Having software either web-based or desktop based to aid researchers citation and documentation management making research-sense. Tailoring to an audience of first year college students by use of features, technology, and portability means capturing a group to increase the relevancy of the aid information professionals can give to future researchers. The information system described above can capitalizes on currently existing designs and technologies in information systems while anticipating new and emerging methods of scholarship citation and documentation management.
The goal is to increase the successful retrieval of information(Tague-Sutcliffe, 1996). If the final aim lies in augmenting, unifying, and adapting the best ideas in emerging information systems, this method can be packaged to that end. Highly simplistic, eminently usable and learnable, the integration with much larger information systems presently in existence or to be created in the future only makes sense. Future researchers will expect to be aided in their quest to manage their information.
References
Buckland 1997.pdf
What is a “document"? Journal of the American Society for Information Science, 48, 9, 804-809.
Saracevic 1995.pdf
Evaluation of evaluation in information retrieval. Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 138-146.
Tague-Sutcliffe 1996.pdf
Some perspectives on the evaluation of information retrieval systems. Journal of the American Society for Information Science, 47, 1, 1-3.
![]()
No comments:
Post a Comment